Proximal Policy Gradient (PPO)
Overview
PPO is one of the most popular DRL algorithms. It runs reasonably fast by leveraging vector (parallel) environments and naturally works well with different action spaces, therefore supporting a variety of games. It also has good sample efficiency compared to algorithms such as DQN.
Original paper:
Reference resources:
- Implementation Matters in Deep Policy Gradients: A Case Study on PPO and TRPO
- What Matters In On-Policy Reinforcement Learning? A Large-Scale Empirical Study
All our PPO implementations below are augmented with the same code-level optimizations presented in openai/baselines's PPO. See The 32 Implementation Details of Proximal Policy Optimization (PPO) Algorithm for more details.
Below are our single-file implementations of PPO:
ppo.py
The ppo.py has the following features:
- Works with the
Boxobservation space of low-level features - Works with the
Discereteaction space - Works with envs like
CartPole-v1
Implementation details
ppo.py includes the 11 core implementation details:
- Vectorized architecture (common/cmd_util.py#L22)
- Orthogonal Initialization of Weights and Constant Initialization of biases (a2c/utils.py#L58))
- The Adam Optimizer's Epsilon Parameter (ppo2/model.py#L100)
- Adam Learning Rate Annealing (ppo2/ppo2.py#L133-L135)
- Generalized Advantage Estimation (ppo2/runner.py#L56-L65)
- Mini-batch Updates (ppo2/ppo2.py#L157-L166)
- Normalization of Advantages (ppo2/model.py#L139)
- Clipped surrogate objective (ppo2/model.py#L81-L86)
- Value Function Loss Clipping (ppo2/model.py#L68-L75)
- Overall Loss and Entropy Bonus (ppo2/model.py#L91)
- Global Gradient Clipping (ppo2/model.py#L102-L108)
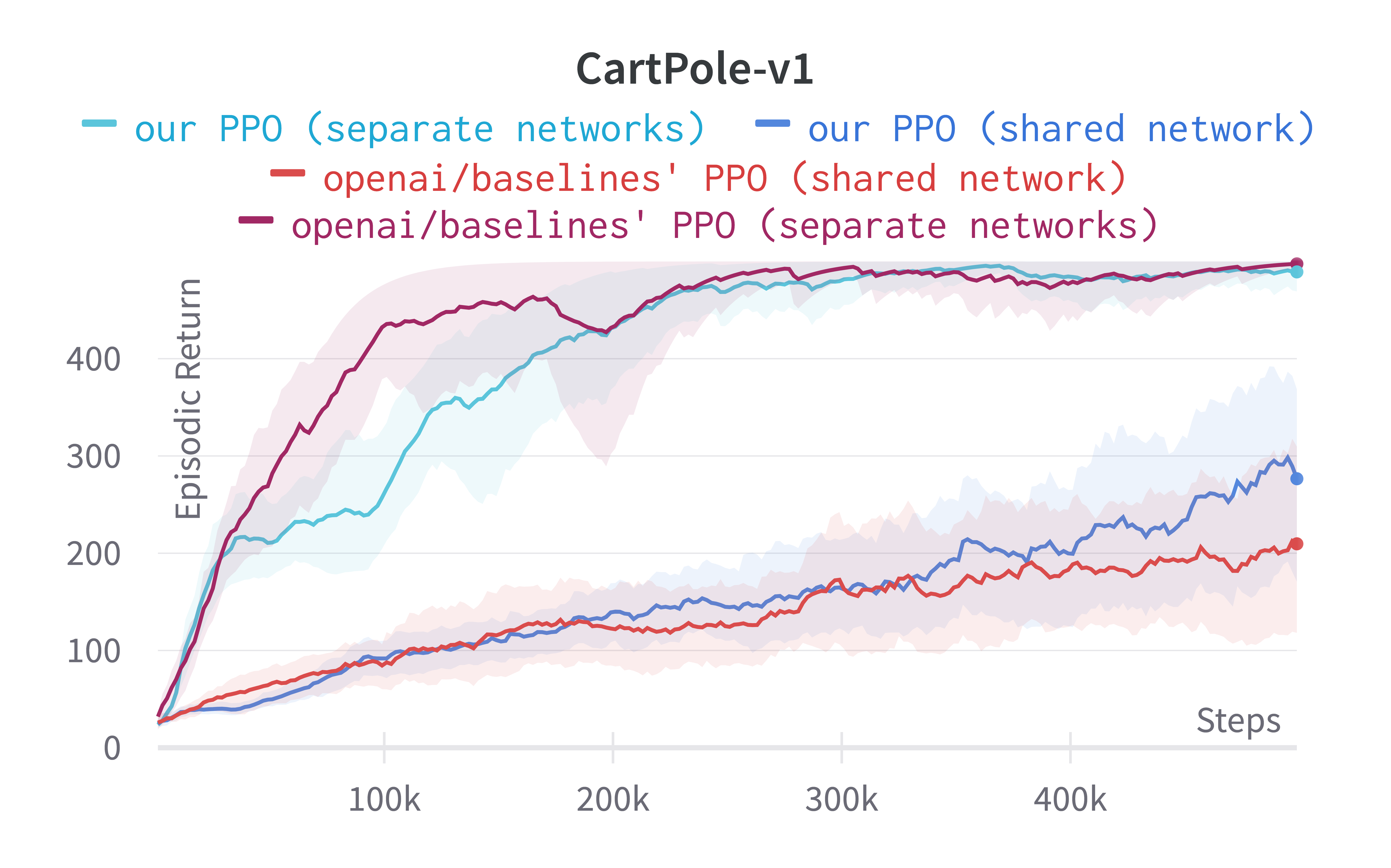
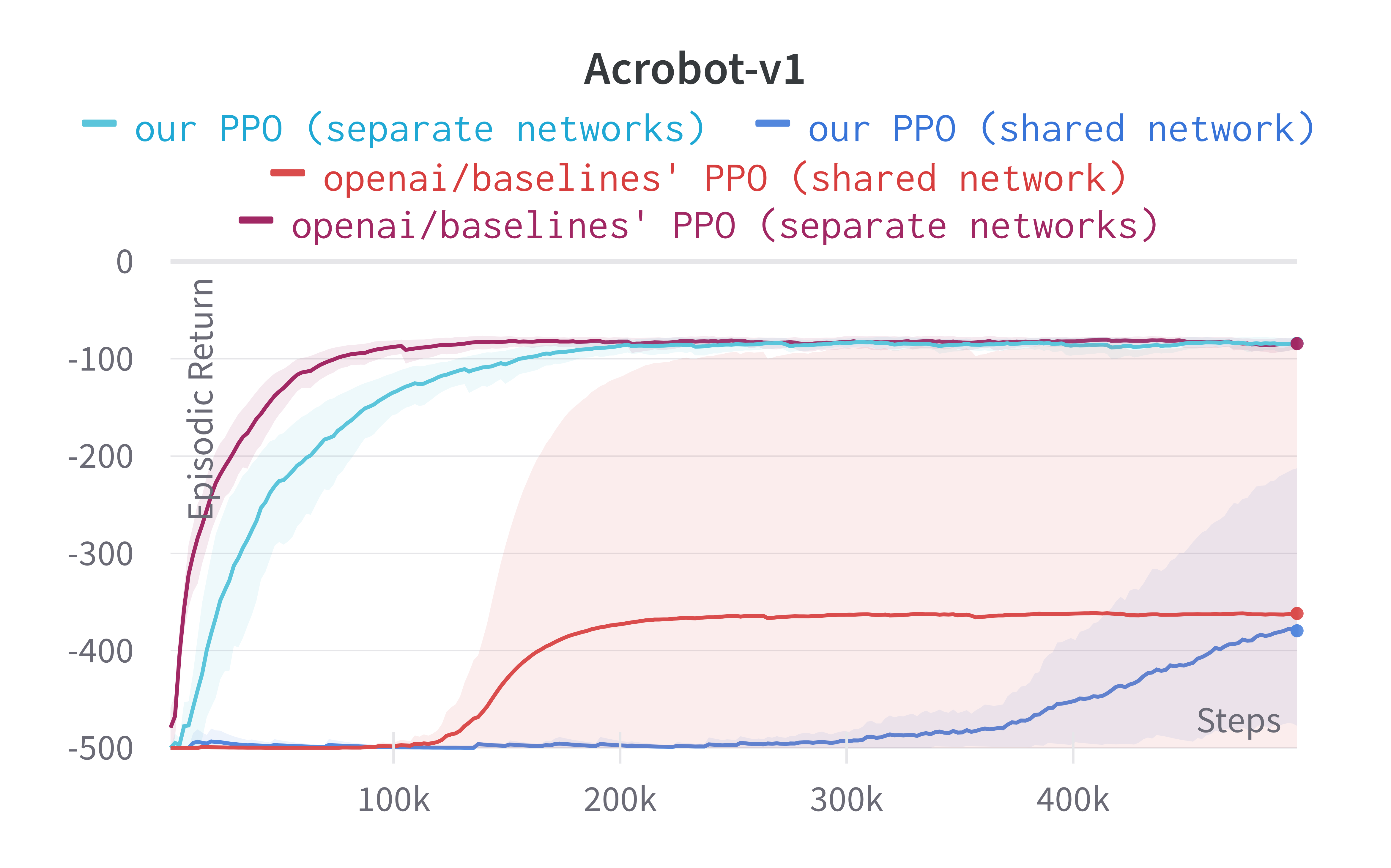
Experiment results
Below are the average episodic return for ppo.py. We compared the results
against openai/baselies' PPO
| Environment | ppo.py |
openai/baselies' PPO |
|---|---|---|
| CartPole-v1 | 488.75 ± 18.40 | 497.54 ± 4.02 |
| Acrobot-v1 | -82.48 ± 5.93 | -81.82 ± 5.58 |
| MountainCar-v0 | -200.00 ± 0.00 | -200.00 ± 0.00 |
Learning curves:
Video tutorial
If you'd like to learn ppo.py in-depth, consider checking out the following video tutorial:

ppo_atari.py
The ppo_atari.py has the following features:
- For playing Atari games. It uses convolutional layers and common atari-based pre-processing techniques.
- Works with the Atari's pixel
Boxobservation space of shape(210, 160, 3) - Works with the
Discereteaction space - Includes the 9 Atari-specific implementation details as shown in the following video tutorial

ppo_continuous_action.py
The ppo_continuous_action.py has the following features:
- For continuous action space. Also implemented Mujoco-specific code-level optimizations
- Works with the
Boxobservation space of low-level features - Works with the
Box(continuous) action space - Includes the 8 implementation details for as shown in the following video tutorial (need fixing)
